树 Tree 相关概念
- 父节点、子节点、兄弟节点、根节点、叶子节点(叶节点)
- 节点的高度(Height)
- 节点到叶子节点的最长路径(边数),从最底层开始计数,计数的起点是 0
- 树的高度 = 根节点的高度
- 节点的深度(Depth)
- 根节点到当前节点所经历的边的个数,从根节点开始度量,计数起点是 0
- 节点的层数(Level)
- 节点的深度 + 1
平衡二叉查找树
- 定义:二叉树中任意一个节点的左右子树的高度相差不能大于 1。
- 目的:解决普通二叉查找树在频繁的插入、删除等动态更新的情况下,出现时间复杂度退化的问题。
- 常见的平衡二叉查找树,AVL 树、Splay Tree(伸展树)、Treap(树堆)
红黑树 Red-Black Tree
- 简称 R-B Tree,是一种不严格的平衡二叉查找树。是为了解决普通二叉查找树在数据更新的过程中,复杂度退化的问题而产生的。
- 红黑树的高度近似 log2n,是近似平衡,插入、删除、查找操作的时间复杂度都是 O(logn)。
- 在红黑树中的节点,一类被标记为黑色,一类被标记为红色。
- 红黑树的要求
- 根节点是黑色的
- 每个叶子节点都是黑色的空节点,也就是说,叶子节点不存储数据(为了简化红黑树的代码实现)
- 任何相邻的节点都不能同时为红色,也就是说,红色节点是被黑色节点隔开的
- 每个节点,从该节点到达其可达叶子节点的所有路径,都包含相同数目的黑色节点
- 用红黑树的高度是否比较稳定地趋近 log2n 来证明红黑树是否是近似平衡的。
左旋(rotate left)、右旋(rotate right)
- 左旋 rotate left,围绕某个节点的左旋
- 右旋 rotate right,围绕某个节点的右旋
红黑树的实现
- 插入操作
- 插入的节点必须是红色的,新插入的节点都是放在叶子节点上
- 如果插入节点的父节点是黑色的,不需要做其他操作
- 如果插入节点是根节点,直接将节点的颜色置为黑色
- 其他情况则需要进入红黑树的平衡调整过程
-
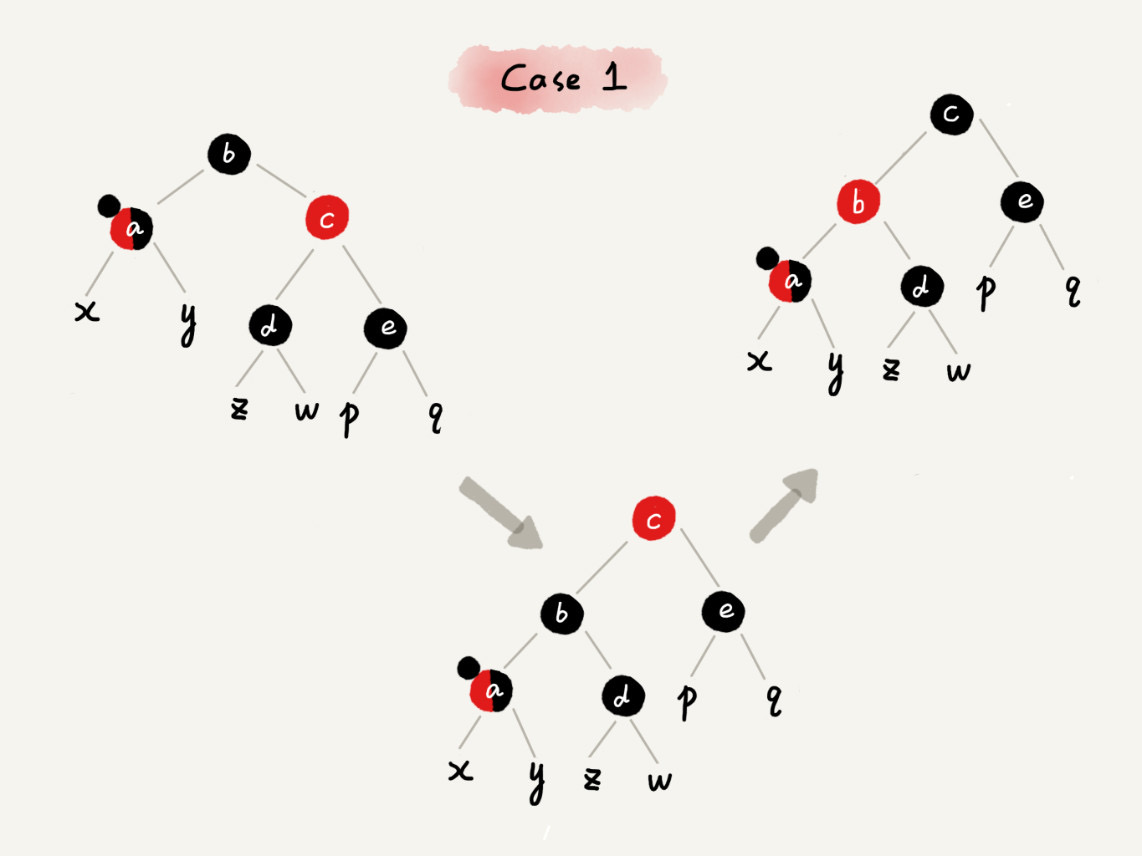
CASE 1:如果关注节点是 a,它的叔叔节点 d 是红色
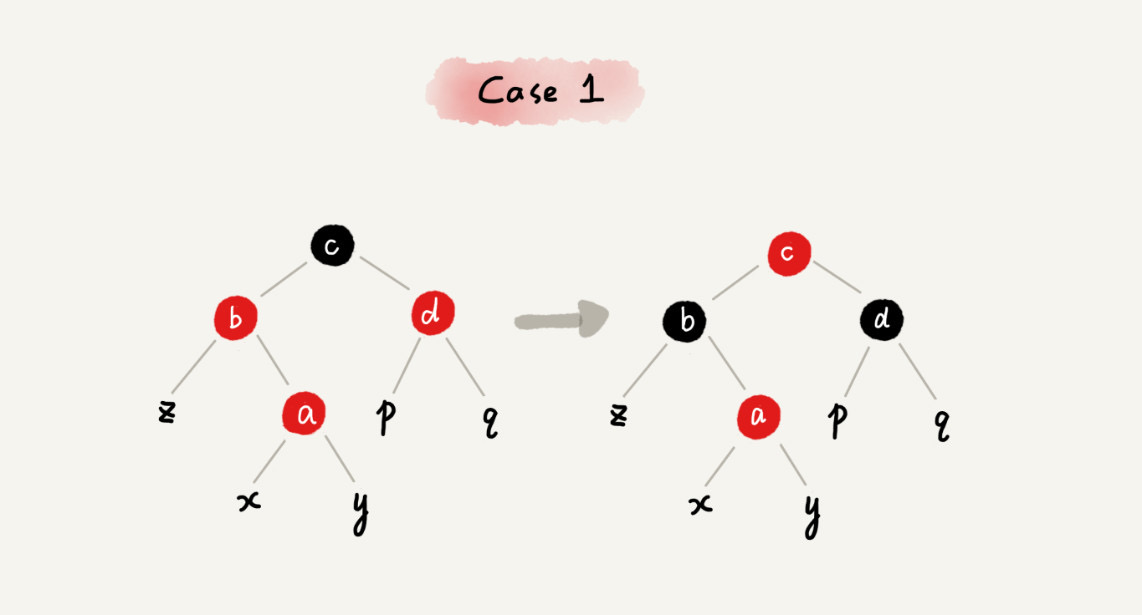
case 1 - 将关注节点 a 的父节点 b、叔叔节点 d 的颜色都设置成黑色
- 将关注节点 a 的祖父节点 c 的颜色设置成红色
- 关注节点变成 a 的祖父节点 c
- 跳到 CASE 2 或 CASE 3
-
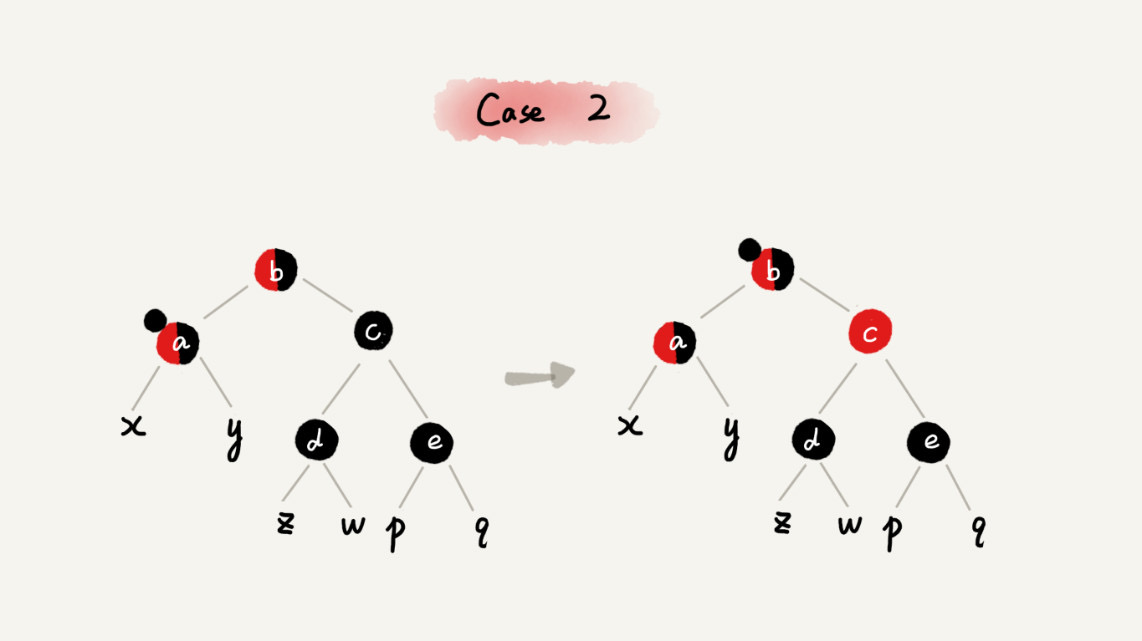
CASE 2:如果关注节点是 a,它的叔叔节点 d 是黑色,关注节点是其父节点 b 的右子节点
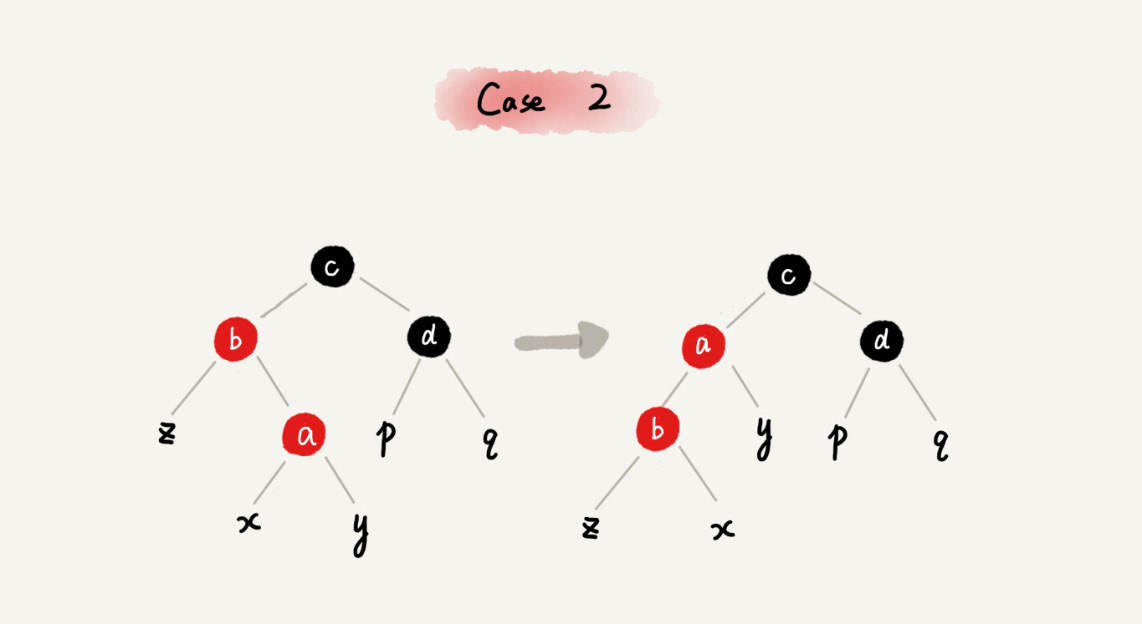
case 2 - 关注节点变成节点 a 的父节点 b
- 围绕新的关注节点 b 左旋
- 跳到 CASE 3
-
CASE 3:如果关注节点是 a,它的叔叔节点 d 是黑色,关注节点 a 是其父节点 b 的左子节点
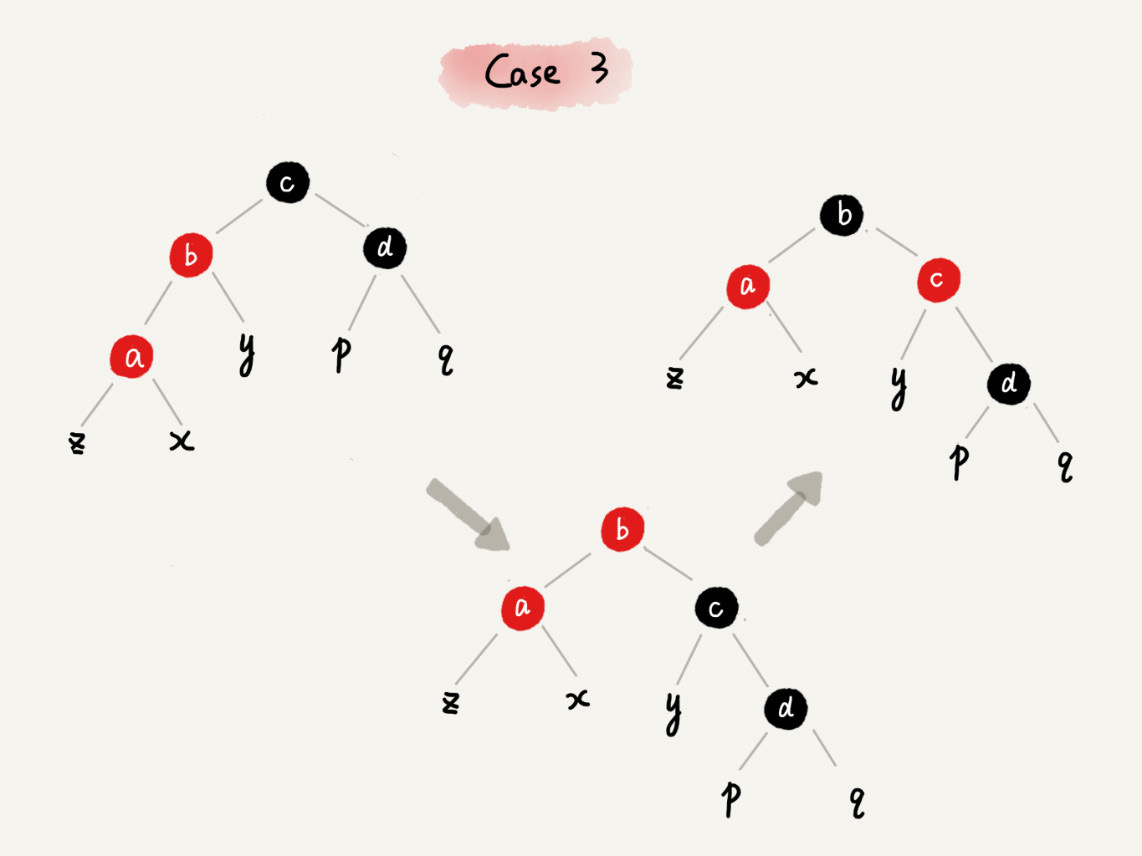
case 3 - 围绕关注节点 a 的祖父节点 c 右旋
- 将关注节点 a 的父节点 b、兄弟节点 c 的颜色互换
-
- 删除操作
- 针对删除节点的初步调整
-
CASE 1:如果要删除的节点是 a,它只有一个子节点 b
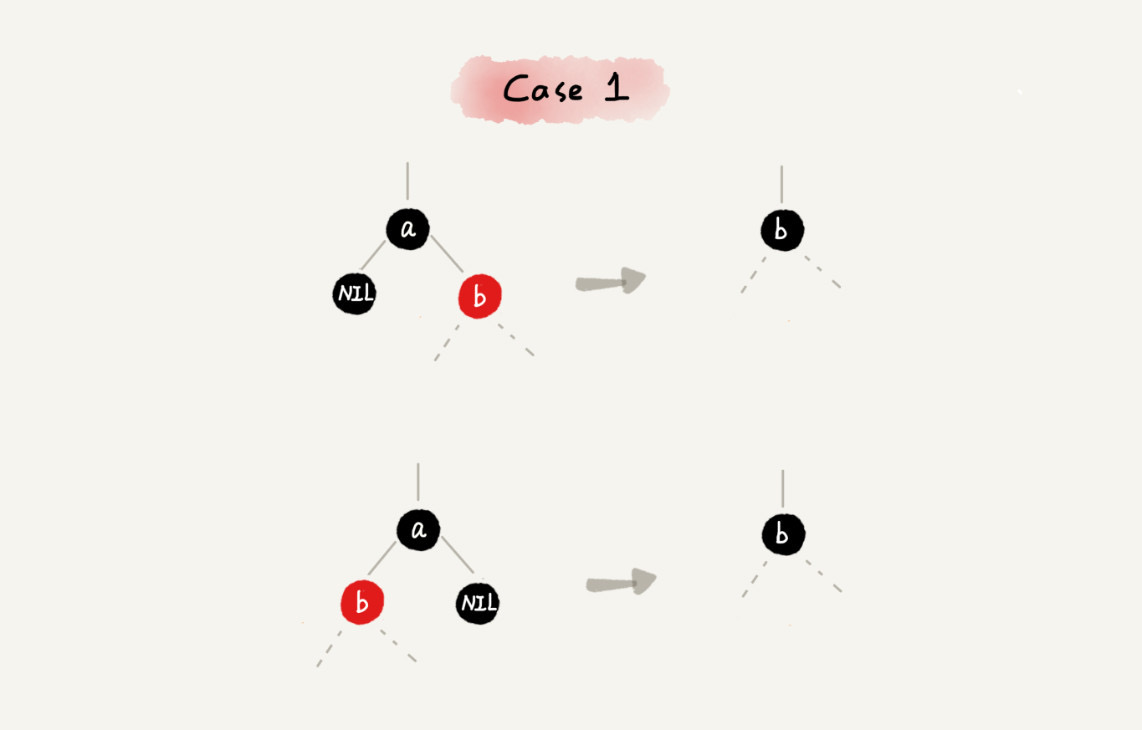
case 1 - 删除节点 a,并且把节点 b 替换道节点 a 的位置
- 节点 a 只能是黑色,节点 b 也只能是红色
-
CASE 2:如果要删除的节点 a 有两个非空子节点,并且它的后继节点就是节点 a 的右子节点 c
case 2 - 如果节点 a 的后继节点就是右子节点 c,那么右子节点 c 肯定没有左子树。将节点 a 删除,并且将节点 c 替换到节点 a 的位置
- 把节点 c 的颜色设置为跟节点 a 相同的颜色
- 如果节点 c 是黑色,将节点 c 的右子节点 d 多加一个黑色
- 将关注节点变成节点 d
-
CASE 3:如果要删除的是节点 a,它有两个非空子节点,并且节点 a 的后继节点不是右节点
case 3 - 找到后继节点 d,并将它删除,删除后继节点 d 的过程参照 CASE 1
- 将节点 a 替换成后继节点 d
- 把节点 d 的颜色设置为跟节点 a 相同的颜色
- 如果节点 d 是黑色,将节点 d 的右子节点 c 多加一个黑色
- 关注节点变成节点 c
-
- 针对关注节点进行二次调整,为了让红黑树中不存在相邻的红色节点
-
CASE 1:如果关注节点是 a,它的兄弟节点 c 是红色的
case 1 - 围绕关注节点 a 的父节点 b 左旋
- 关注节点 a 的父节点 b 和祖父节点 c 交换颜色
- 关注节点不变
-
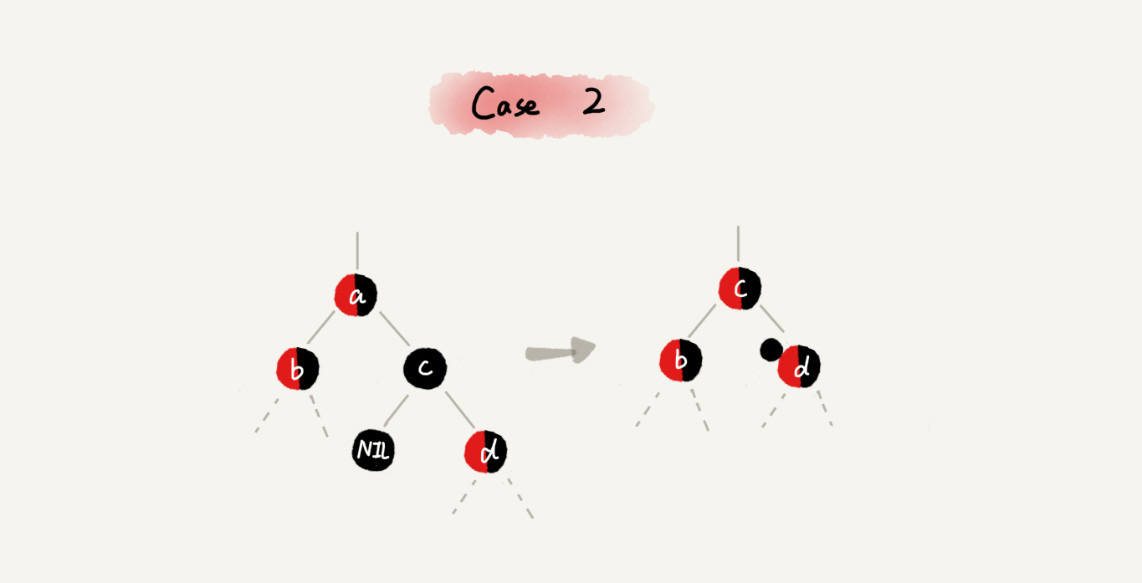
CASE 2:如果关注节点是 a,它的兄弟节点 c 是黑色的,并且节点 c 的左右子节点 d、e 都是黑色的
case 2 - 将关注节点 a 的兄弟节点 c 的颜色变成红色
- 从关注节点 a 中去掉一个黑色,这个时候节点 a 就是单纯的红色或黑色
- 给关注节点 a 的父节点 b 添加一个黑色节点
- 关注节点从 a 变成其父节点 b
-
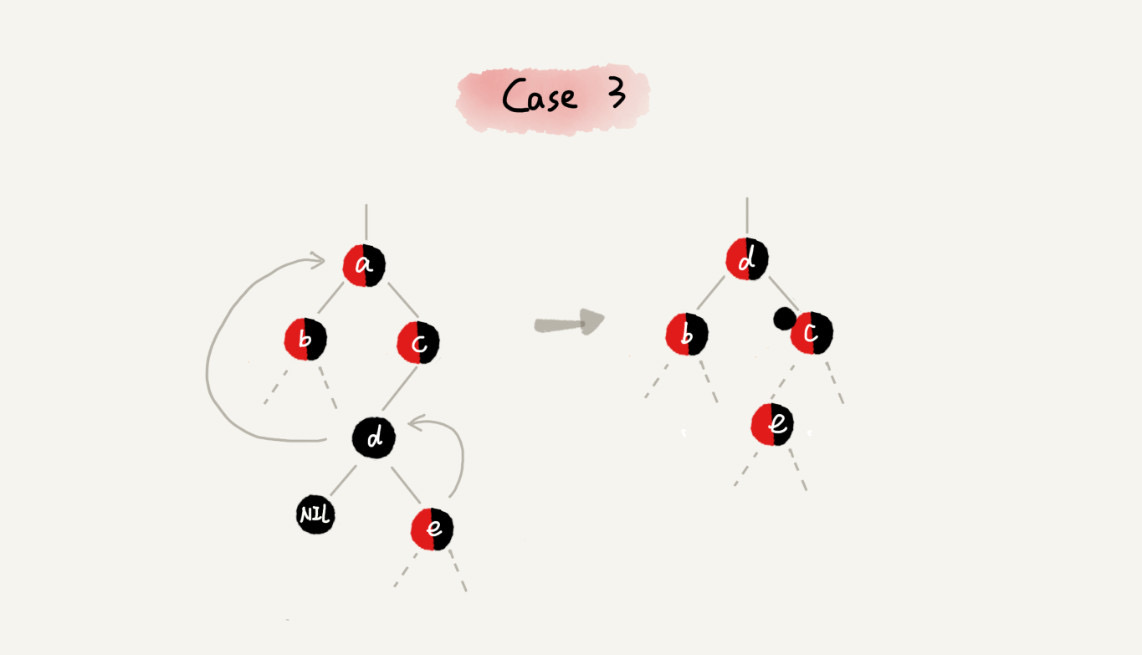
CASE 3:如果关注节点是 a,它的兄弟节点 c 是黑色,c 的左子节点 d 是红色,c 的右子节点 e 是黑色
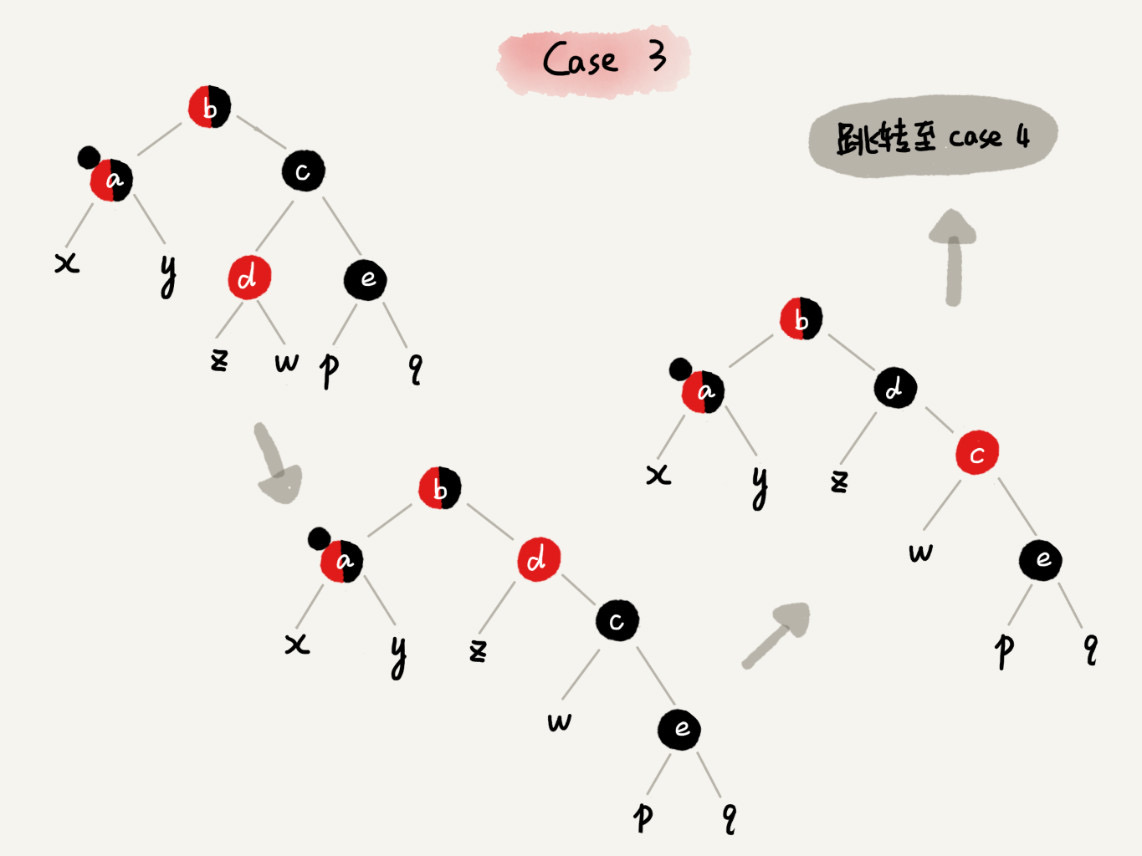
case 3 - 围绕关注节点 a 的兄弟节点 c 右旋
- 节点 c 和节点 d 交换颜色
- 关注节点不变
- 跳转到 CASE 4
-
CASE 4:如果关注节点 a 的兄弟节点 c 是黑色的,并且 c 的右子节点是红色的
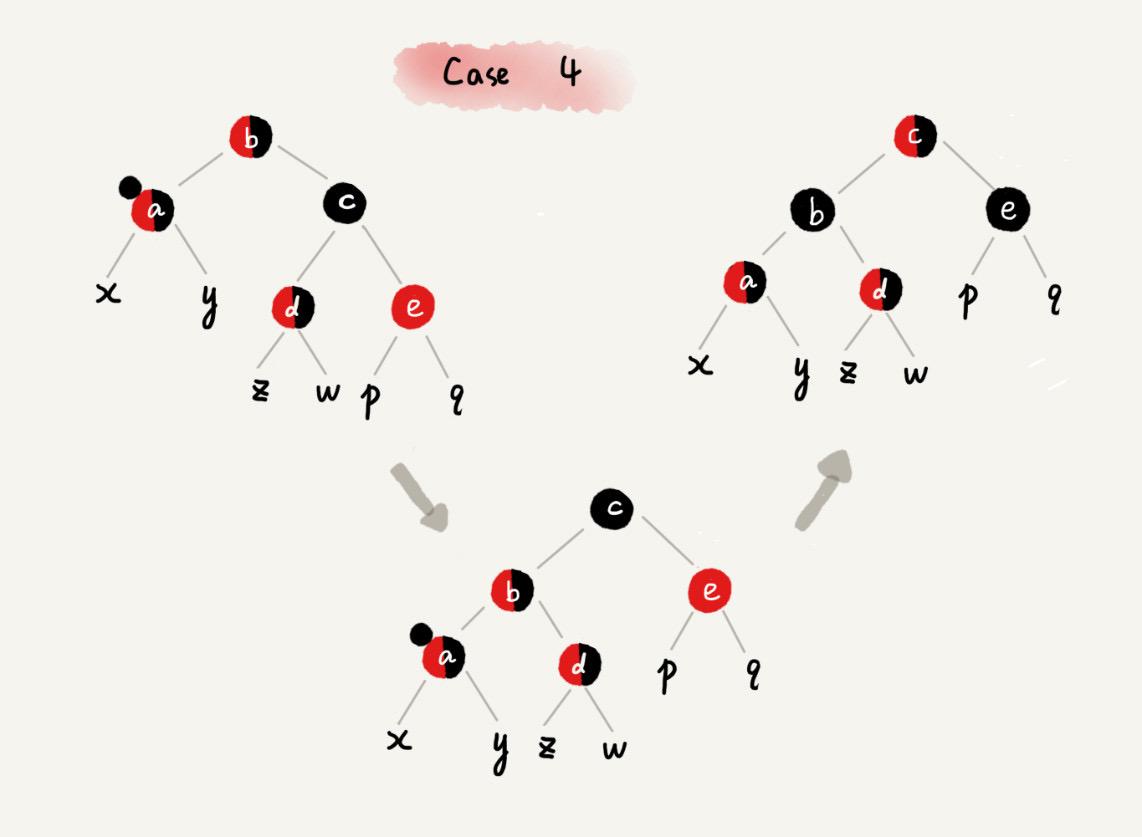
case 4 - 围绕关注节点 a 的父节点 b 左旋
- 将关注节点 a 的兄弟节点 c 的颜色,跟关注节点 a 的父节点 b 设置成相同的颜色
- 将关注节点 a 的父节点 b 的颜色设置为黑色
- 从关注节点 a 中去掉一个黑色,节点 a 就变成了单纯的红色或者黑色
- 将关注节点 a 的叔叔节点 e 设置为黑色
-
- 针对删除节点的初步调整
参考资料
- https://blog.csdn.net/fei33423/article/details/79132930
- https://blog.csdn.net/abcdef314159/article/details/77193888
堆 Heap
- 堆是一种特殊的树,是一个完全二叉树
- 堆中每一个节点的值都必须大于等于(或小于等于)其子树中每个节点的值,大顶堆、小顶堆
堆的实现
- 堆是一个完全二叉树,使用数组来存储,节省存储空间。直接通过数组的下标,找到对应节点的左右子节点和父节点
- 堆的操作
- 插入元素(堆化),时间复杂度 O(logn)
- 从下往上的堆化,遇到不满足大小条件的就交换父子节点
- 从上往下的堆化,遇到不满足大小条件的就交换父子节点
- 删除堆顶元素
- 从上往下的堆化,时间复杂度 O(logn)
- 将最后一个数字放在堆顶,遇到不满足大小条件的就交换父子节点
- 从上往下的堆化,时间复杂度 O(logn)
- 插入元素(堆化),时间复杂度 O(logn)
基于堆实现排序
- 建堆,时间复杂度,O(n)
- 将数组原地建成一个堆,直接在原数组上操作
- 方式
- 从前往后处理数组数据,从下往上的堆化。不断地在堆中插入元素,对堆进行插入操作
- 从后往前处理数组数据,从上往下的堆化。从非叶子节点开始,依次堆化。
- 对于完全二叉树来说,下标从 n/2 + 1 到 n 的都是叶子节点
- 排序,时间复杂度,O(nlogn)
- 堆顶(数组中的第一个元素)就是最大的元素
- 删除堆顶元素,将堆顶和最后一个元素交换,最大元素放在下标为 n 的位置
- 将剩下的 n - 1 个元素重新构建成堆
- 重复上述操作
- 堆排序整体的时间复杂度是O(nlogn),不是稳定的排序算法
为什么快速排序比堆排序性能好(时间复杂度同样为O(nlogn))
- 堆排序数据访问的方式没有快速排序友好
- 快速排序的数据是顺序访问的,而堆排序是跳着访问的,对 CPU 缓存不友好
- 对于同样的数据,在排序过程中,堆排序算法的数据交换次数要多于快速排序
堆的应用
- 堆排序
- 求 topK
- 流里面的中值
- 流里面的中位数
- 优先级队列
优先级队列
- 思路:数据的出队顺序按照优先级高的先出队
- 实现
- 一个堆就可以看作是一个优先级队列
- 在优先级队列中,执行入队操作,就相当于往堆中插入一个元素。执行出队操作,相当于取出堆顶元素。
- 应用场景
- 合并有序小文件
- 假设有 100 个小文件,每个文件的大小是 100 MB,每个文件中存储的都是有序的字符串。将这 100 个小文件合并成一个大文件
- 使用数组的实现
- 从这 100 个文件中,各取第一个字符串,放入数组中,比较大小,把最小的字符串放入合并后的大文件中,并将它从数组中删除。
- 假设这个最小的字符串来自 13.txt,就从这个文件中取下一个字符串,放入数组中。重新比较大小,选择最小的放入合并后的大文件,将它从数组中删除。
- 重复上述步骤,直至所有文件中的数据都放入到大文件为止。
- 使用优先队列的实现
- 和使用数组的方法类似,只不过将从文件中取出的字符串放在小顶堆中。
- 删除堆顶元素,即最小的元素。然后再从堆顶元素所在的文件当中取出下一个字符串,放入堆中。
- 重复上述步骤,直至所有文件中的数据都放入到大文件为止。
- 高性能定时器
- 假设定时器中维护了很多定时任务,每个任务都设定了一个要出发执行的时间点。
- 简单粗暴的实现
- 每隔一个很小的单位时间(如 1 秒)扫描一遍任务列表,检查是否有任务达到设定的执行时间。如果达到了,就执行任务。
- 使用堆的实现
- 按照任务设定的执行时间,将这些任务存储在优先队列中,队列首部(小顶堆的堆顶)存储的是最先执行的任务。
- 将队列首部任务的执行时间与当前时间相减,得到时间间隔 T。即从当前开始,第一个任务执行需要等待的时间。
- 时间 T 过去后,定时器取优先级队列中队列首部的执行任务。
- 移除队列首部任务,然后再计算新的队列首部任务的执行时间点与当前时间点的差值。
- 合并有序小文件
求 Top K
- 静态数据集合
- 例:如何在包含 n 个数据的数组中,查找前 K 大的数据
- 使用小顶堆,维护一个大小为 K 的小顶堆
- 实现:顺序遍历数组,从数组中取出数据与堆顶元素比较,如果比堆顶元素大,则把堆顶元素删除,并将这个数据插入到堆中。如果比堆顶元素小,则不做任何处理,继续遍历数组。
- 时间复杂度
- 遍历数组:O(n)
- 堆化:O(logK)
- 所以总共是 O(nlogK)
- 动态数据集合
- 例:数据集合有两个操作,一个是添加数据,一个是查询当前 K 大数据
- 一直维护一个 K 大小的小顶堆
- 实现:当有数据被添加到集合中时,与堆顶元素比较大小。如果比堆顶元素大,则把堆顶元素删除,并将这个元素插入堆中。如果比堆顶元素小,则不做处理。
利用堆求中位数
- 静态数据集合
- 先排序,取下标 n / 2 的数据
- 动态数据集合
- 维护两个堆,一个大顶堆,一个小顶堆
- 大顶堆中存储前半部分数据,小顶堆中存储后半部分数据,且小顶堆中的数据都大于大顶堆中的数据
- 中位数就是大顶堆的堆顶元素
- 实现:
- n 个数据,如果 n 是偶数,按照从小到大排序,前 n / 2 个数据存储在大顶堆中,后 n / 2 个数据存储在小顶堆中。如果 n 是奇数,大顶堆存储 n / 2 + 1 个数据,小顶堆中存储 n / 2 个数据
- 如果新加入的数据小于等于大顶堆的堆顶元素,将这个数据插入到大顶堆,否则,将这个数据插入到小顶堆
- 当不满足大顶堆和小顶堆的数据个数时,通过将一个堆中不停地将堆顶元素移动到另一个堆,来满足数据个数的要求
- 延伸:如何快速求 n% 的数据,例:如何快速求接口的 99% 响应时间
- 使用两个堆,一个大顶堆,一个小顶堆。大顶堆中保存前 n% 的数据,小顶堆中保存 1 - n% 的数据。大顶堆堆顶的数据就是要求的数据。
- 每次插入一个数据的时候,判断这个数据跟大顶堆堆顶数据和小顶堆堆顶数据的大小关系。如果新插入的数据比大顶堆的堆顶数据小,则插入大顶堆。如果新插入的数据比小顶堆的堆顶数据大,则插入小顶堆。
- 每次插入数据后,需要重新计算大顶堆和小顶堆的数据格式,看看是否还满足要求。如果不满足,就将一个堆中的数据移动到另一个堆中,直到满足要求。