拓扑排序 Topological Sorting
- 当一组数据间存在两两依赖关系,并且数据间不存在循环依赖的关系。如果要对这组数据进行排序,则可以使用拓扑排序
- 拓扑排序是基于有向无环图的算法
- 需要通过局部顺序来推导出全局顺序的,使用拓扑排序来实现
拓扑排序的实现方式
-
Kahn 算法
- 如果 s 先于 t 执行,则添加一条 从 s 指向 t 的边
- 若某个顶点的入度为 0,说明没有任何一个顶点需要先于此顶点执行,则此顶点可以先执行
- 在图中找出入度为 0 的顶点,输出并在图中删除此顶点,也就是把这个顶点可达的顶点的入度都 - 1
- 若输出的顶点个数少于图中的顶点个数,并且图中还存在入度不为 0 的顶点,则说明此图中存在环
-
DFS 深度优先遍历算法
- 构造逆邻接表,如果 s 先于 t 执行,则添加一条 从 t 指向 s 的边
- 递归的处理每个顶点,先输出这个顶点可到达的顶点后,再输入此顶点
Dijkstra 最短路径算法
- 单源最短路径算法,即 求一个顶点到另一个顶点的最短路径
- Dijkstra 是基于有向有权图
- Dijkstra 的时间复杂度为 O(E * logV),E 表示边的个数,V 表示顶点个数
Dijkstra 算法的实现
- 使用邻接表(邻接矩阵)来表示有向有权图
- 每个结点包括起始顶点 s 、结束顶点 t 、权重 w,即 s -> t
- 使用一个数组来表示从顶点 s 到此顶点 n 的最小距离
- 每个结点包括起始顶点 s 、当前顶点 n 、s 到 n 的最小距离 dist
- 初始起点顶点的 dist 为 0,其余顶点的初始 dist 的值为无限大
- 根据 dist 构造一个小顶堆,每次优先获取 dist 最小的顶点
- 初始 dist 小顶堆只有起始顶点,遍历其余顶点时不断更新 dist 小顶堆
- dist 小顶堆中存放的是已经遍历过且计算出 dist 的顶点
- 使用一个数组来表示此顶点是否已经被遍历过
- 如果已经遍历过,且发现到达此顶点的更短路径,则更新 dist 的小顶堆
- 如果没遍历过,将此顶点加入到 dist 的小顶堆中
- 使用一个数组来表示最短路径,记录每个顶点的前驱顶点
Dijkstra 的优化
- 当在较大的地图上,计算两点之间的最短路径时
- 如果两点间的距离较近,可以在整个大地图中划分出一个小的区块,这个小区块可以覆盖这两个点,但是区域不会太大
- 如果两点间的距离较远,可以把两点所在的大区域当作一个点,先计算两个大区域的路线,然后再细化每个阶段的小路线
- 计算两点间所用最少时间
- 将边的权重改为经过这段路所需要的时间
- 计算两点之间所经过最少红绿灯
- 将每条边的权重值改为 1,或者直接使用广度优先搜索算法
Dijkstra 算法的变形和应用
-
背景
- 单词经过翻译系统后,得到单词对应的释义及分数,分数代表翻译的可信程度。将句子中的单词翻译后相加,可以得到整句的翻译分数。希望求得翻译得分的 TOP k
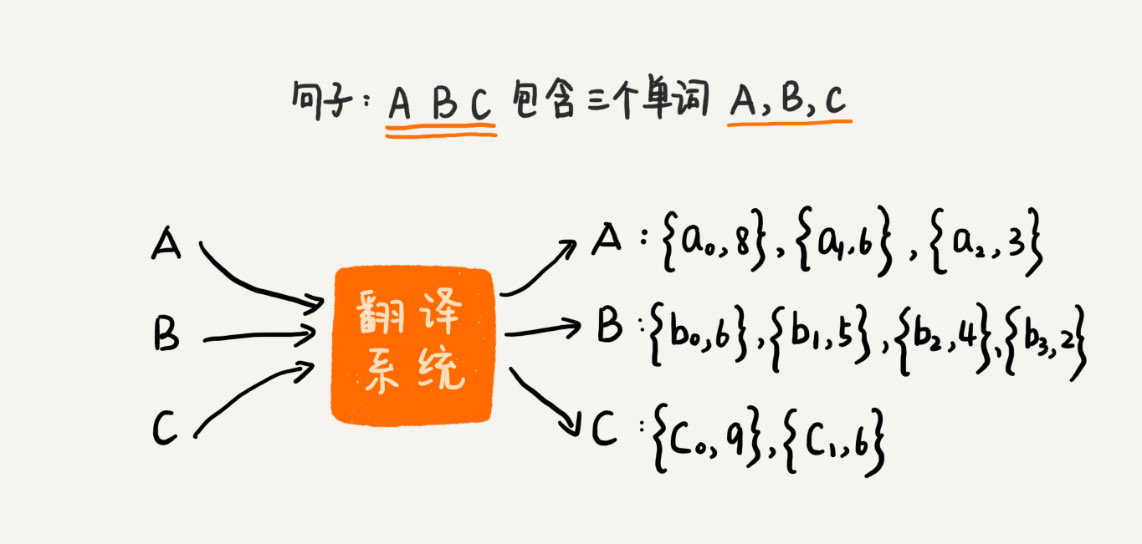
Dijkstra
- 单词经过翻译系统后,得到单词对应的释义及分数,分数代表翻译的可信程度。将句子中的单词翻译后相加,可以得到整句的翻译分数。希望求得翻译得分的 TOP k
-
实现
- 回溯算法
- 穷举所有的排列组合情况,选取得分最高的前 k 个翻译结果
- 时间复杂度为 O(mn),m 表示每个单词的平均可选翻译个数,n 表示单词数
- Dijkstra 算法
- 首先可以得到得分最高的一个组合,基于此组合来进行扩展,将每个单词的翻译分别替换成下一个得分最高的翻译。假设为 a0b0c0,扩展后为:a1b0c0、a0b1c0、a0b0c1
- 每次从优先级队列(大顶堆)中取出
- 回溯算法