过滤器
- 过滤重复的数据
- 位图
- 布隆过滤器
- 过滤、拦截数据(如 短信、邮件等)
- 基于黑名单的过滤器
- 基于规则的过滤器
- 基于概率统计的过滤器
布隆过滤器 Bloom Filter
位图 Bit Map
- 位图是一种“特殊”的散列表,使用一个二进制位(bit)来表示一个布尔类型,通过位运算来实现对 bit 的使用
- 位图通过数组下标来定位数据,访问效率高,需要的内存小
- 1 Byte = 8 bit, 1 KB = 1024 B,1 MB = 1024 KB,1 GB = 1024 MB
位图与布隆过滤器
- 位图适合数据个数和数据范围的差值不大的情况
- 当差值过大时,位图需要的存储空间可能超过使用散列表存储的空间
- 若通过哈希函数对数字处理,使得数字落在一个合适的数据范围内,则可能出现哈希冲突
- 布隆过滤器
- 布隆过滤器是基于位图的改进,为了处理数据个数和数据范围的差值过大的情况
- 布隆过滤器存在误判,当判断不存在时一定不存在,而判断存在时可能存在,也可能不存在
- 布隆过滤器一般不用删除数据,如果要支持删除操作,可以额外使用其他的数据结构用来记录删除的数据
布隆过滤器 Bloom Filter
- 使用 K 个哈希函数,对同一个数字分别使用这 K 个哈希函数求哈希值,分别为 X1、X2、X3 …. Xk,将求得的这 K 个哈希值的下标都置为 true,用 K 个二进制位来表示一个数字的存在
- 查询数字是否存在时,使用同样的 K 个哈希函数求哈希值,通过这 K 个哈希值对应位图中的数值是否都为 true,如果都是 true 则说明这个数字存在,如果其中有任意一个不为 true,则说明这个数字不存在
- 布隆过滤器会出现误判的情况,但只会对存在的情况发生误判。如果某个数字经过布隆过滤器判断不存在,则这个数字一定不存在,而某个数字经过布隆过滤器判断为存在,则这个数字可能存在,也可能不存在
- 降低布隆过滤器误判概率的方法
- 增加哈希函数的个数
- 增加位图的大小和存储数字的个数之间的比例
- 在数据个数与位图大小的比例超过一定阈值的时候,可以重新申请一个新的位图。当需要判断某个数据是否存在时,需要查看多个位图
- 布隆过滤器 vs 散列表
- 布隆过滤器使用多个哈希函数对同一个数据进行处理,CPU 只需要从内存中读取一次,进行多次哈希运算,属于 CPU 密集型操作
- 散列表中可能存在散列冲突,当出现散列冲突时,需要读取散列值相同的多个数据,并跟原数据进行对比,属于内存密集型操作
- 理论上来看,布隆过滤器比散列表更加快速
布隆过滤器的应用
- 判断是否存在
- 爬虫网页的去重
- 快速判断某个数字是否存在于数据中
- 统计大型网站的每日 UV 数,对重复访问的用户去重
过滤、拦截器
基于黑名单的过滤器
- 动态维护一个发送方信息的黑名单,即判断是否为黑名单的数据来源,如骚扰电话号码和垃圾短信发送号码、IP 地址等
- 若黑名单的数据量不大,可以使用散列表、二叉树等动态数据结构存储
- 若黑名单的数据量很大
- 使用布隆过滤器来减少所占用内存的大小,缺点是可能存在误判
- 将黑名单存储在服务器上,手机端将需要检查的号码发送给服务器端,完全不需要占用手机内存,缺点是必须联网工作,且网络延迟会降低处理速度
基于规则的过滤器
- 通过内容判断是否为垃圾信息,基于人工制定的规则
- 内容包含特殊单词
- 发送号码为群发号码
- 包含回拨的联系方式,如网页链接、QQ、微信等
- 格式花哨、内容很长,包含表情、图片、网页链接等
- 符合已知的垃圾内容的模版
- 结合多条规则综合来判断是否为垃圾信息
- 符合 N 条以上
- 每个规则对应不同的得分,总得分超过一定数值
- 基于概率统计的方法判断是否为垃圾信息
- 有大量的样本数据,且样本数据已经做好了标记,是否为垃圾信息
- 对样本信息进行分词处理,去掉“的、和、是”等没有意义的停用词(Stop Words),得到 n 个不同的单词
- 针对每个单词,统计此单词出现在有多少个垃圾信息中,即此单词出现在垃圾信息中的概率
- 如果此单词出现在垃圾信息中的概率远大于出现在非垃圾短信中的概率,则标记此单词为“垃圾单词”
- 缺点
- 人工制定的规则受人思维方式的限制,规则简单、局限
- 垃圾内容发送方可能会针对这些规则,精心设计内容,绕过这些规则的拦截
基于概率统计的过滤器
基于朴素贝叶斯算法 Native Bayesian Classification
-
使用概率来表示一个内容是垃圾信息的可信程度,将内容抽象成一组计算机可识别且可计算的特征项,用这一组特征项来代替内容本身
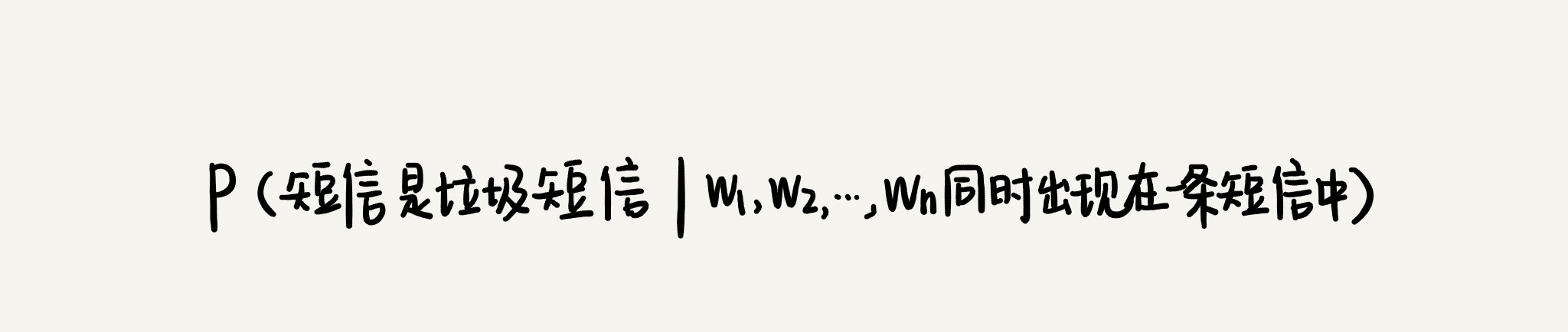
概率 -
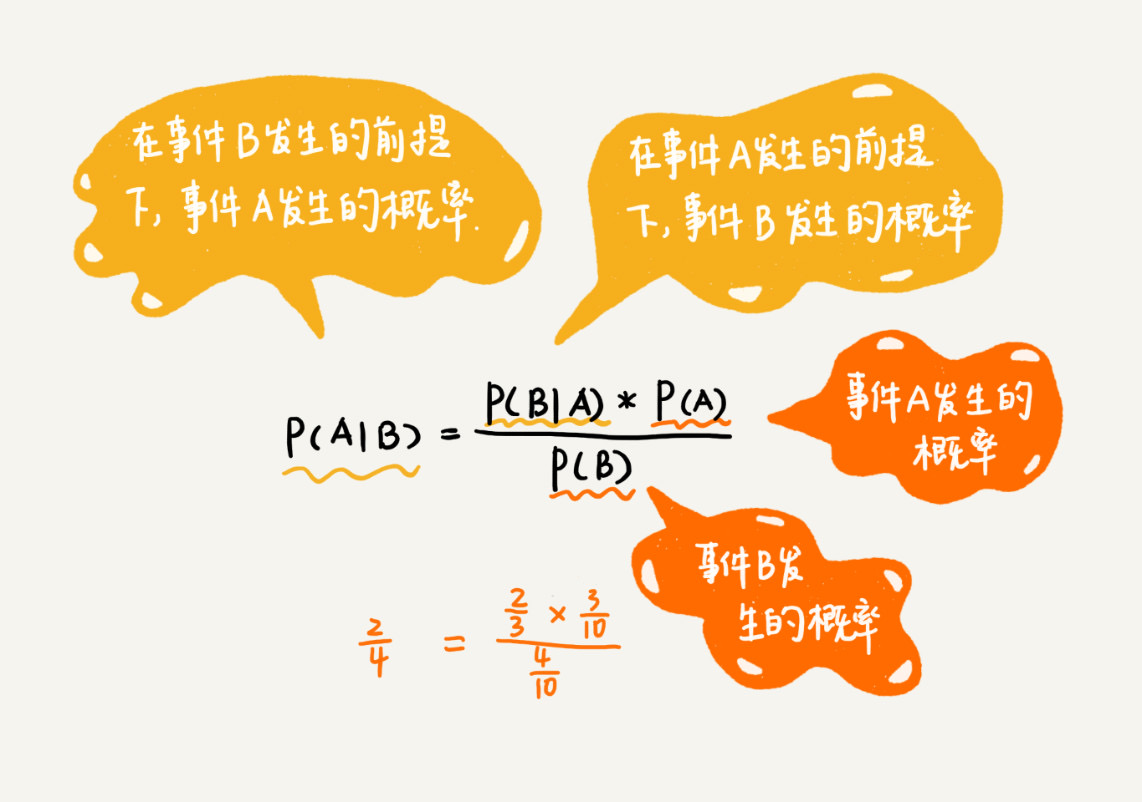
利用朴素贝叶斯公式计算出概率
-
独立事件发生的概率计算公式:P(A*B) = P(A)*P(B)
-
如果事件 A 和事件 B 是独立事件,两者的发生没有相关性,事件 A 发生的概率 P(A) 等于 p1,事件 B 发生的概率 P(B) 等于 p2,那两个同时发生的概率 P(A*B) 就等于 P(A)*P(B)

计算概率 
计算概率
-
-
计算同时包含 W1,W2,W3,…,Wn, 这 n 个单词的内容,是垃圾信息的概率 P1 和非垃圾信息的概率 P2,利用 P1 和 P2 的比值来判断此内容是否为垃圾信息
-
P(W1,W2,W3,…,Wn 同时出现在一条短信中) 在计算 P1 和 P2 的比值中抵消了

计算概率
-
实际应用
- 可以结合上述三种不同的过滤拦截方式的结果,对同一个内容处理,如果三者都表明是垃圾信息,则过滤拦截
- 不断地调整策略
- 准确率,是否会把不是垃圾的短信错判为垃圾短信
- 召回率,是否能把所有的垃圾短信都找到