鉴权
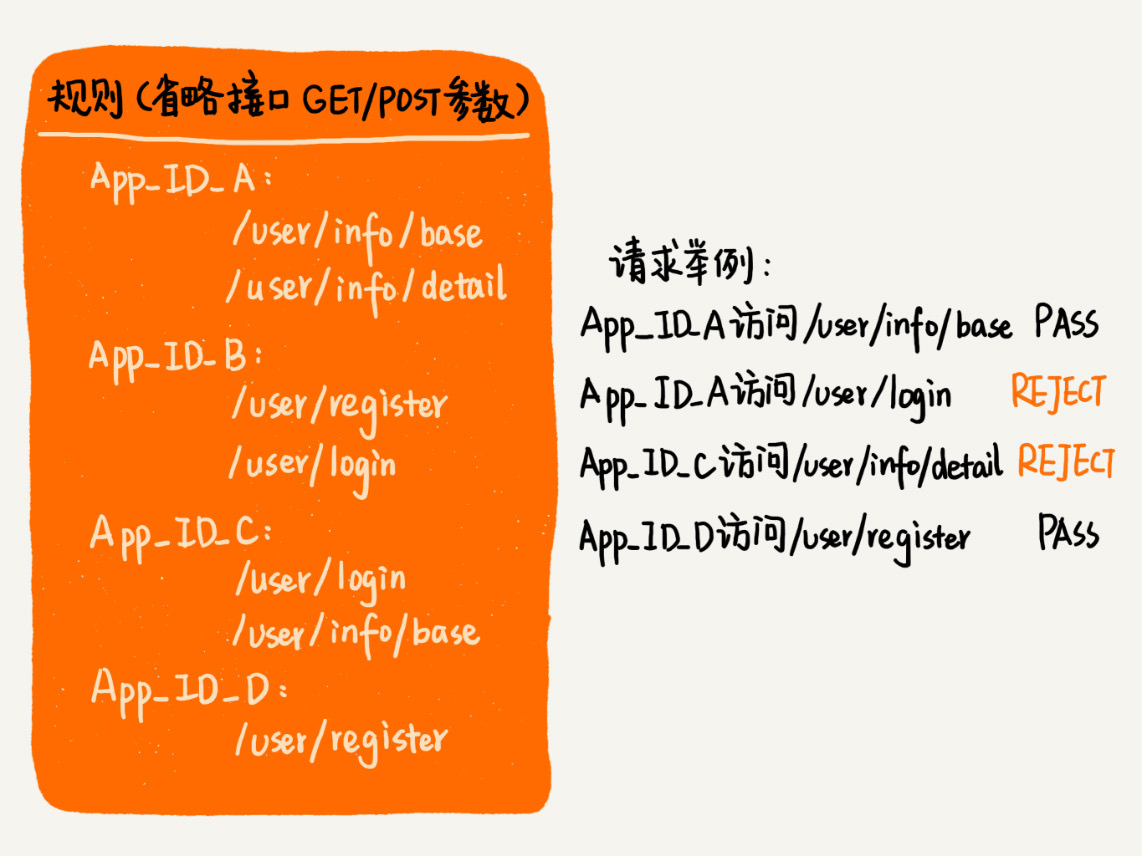
1.精确匹配规则
- 使用散列表存储,不同应用对应的不同规则关系
- 当需要匹配时
- 暴力匹配:可以将请求 URL 和字符串数组中逐一匹配,使用字符串匹配算法 KMP、BM、BF 等
- 快速匹配:将所有规则按照字符串大小排序,存储成一个有序数组,当要匹配时,使用二分查找,在有序数组中匹配
-
前缀匹配规则
-
使用散列表存储,不同应用对应的不同规则关系
-
当需要匹配时
- 暴力匹配
- 快速匹配:使用 Trie 树来存储所有字符串规则,Trie 树中的每个节点不是存储单个字符串,而是存储接口被“/”分割之后的子目录,并且将每个节点的子节点存储成有序数组,在匹配的过程中,可以利用二分查找算法,决定下一个节点

前缀匹配规则 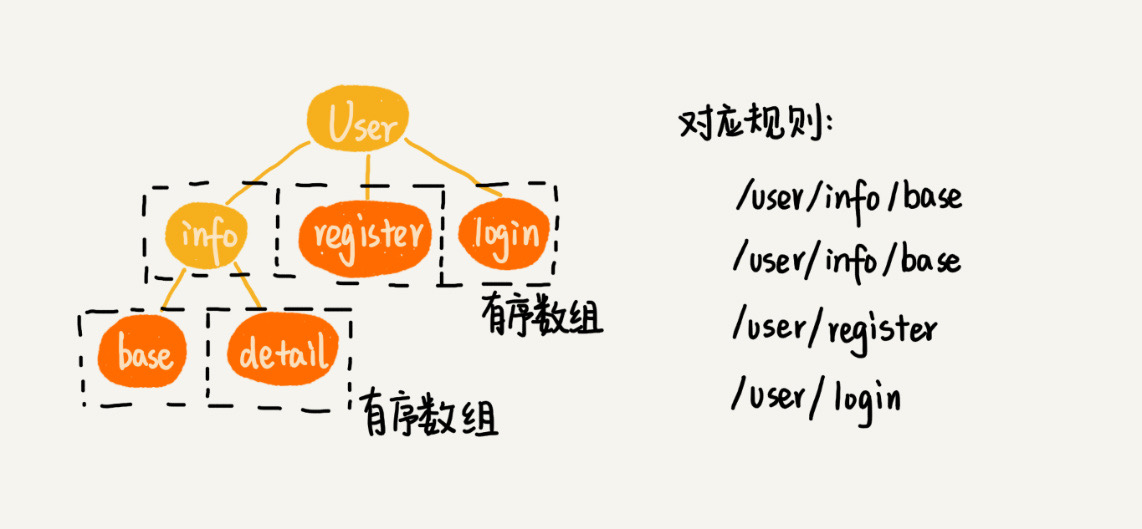
前缀匹配规则
-
-
模糊匹配规则
-
使用散列表存储,不同应用对应的不同规则关系
-
当需要匹配时
- 暴力匹配:使用回溯的思想来匹配通配符
- 快速匹配:将包含通配符和不包含通配符的规则分开处理,不包含通配符的规则,存成有序数组或 Trie 树,剩余的包含通配符的规则,存储在数组中。当收到请求时,先在不包含通配符的有序数组或 Trie 树中匹配,如果可以匹配成功,则返回,如果不能匹配,则继续在通配符规则中匹配

模糊匹配规则
-
限流
-
固定时间窗口限流算法
-
思想
- 选定一个时间起点,之后收到请求时将计数器加一
- 根据限流规则,如果在当前时间窗口内,累计访问次数超过限流值,则拒绝后续的访问请求
- 当进入下一个时间窗口时,计数器清零重新计数
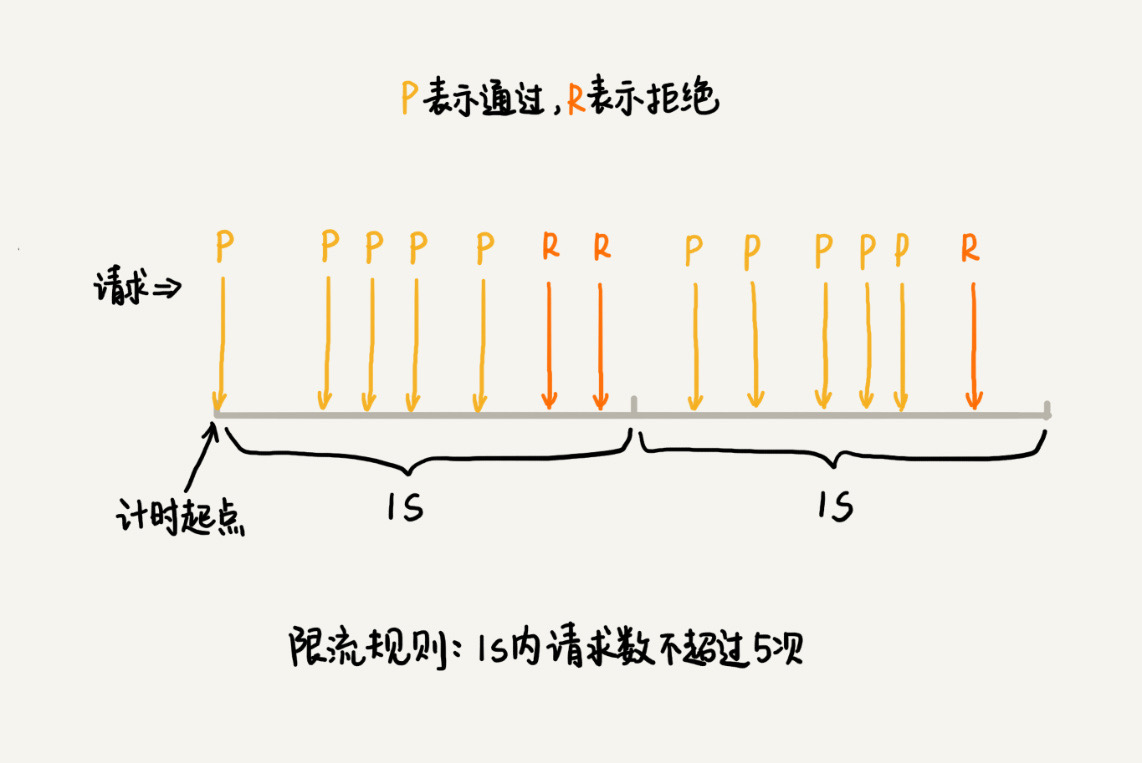
固定时间窗口 -
缺点
- 限流策略过于粗略,无法应对两个时间窗口临界时间内的突发流量
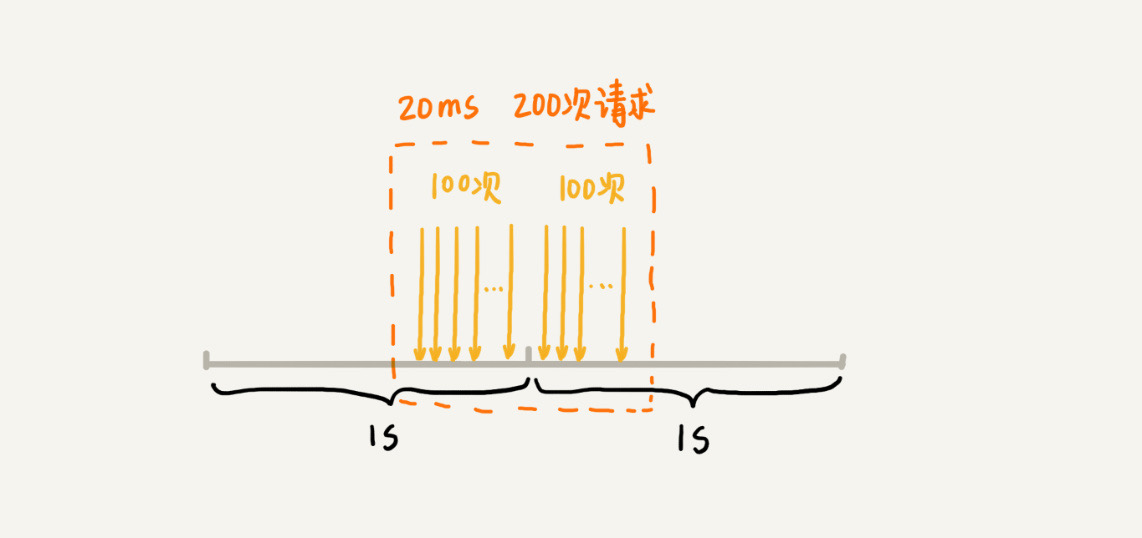
缺点
-
-
滑动时间窗口限流算法
-
假设限流的规则为,在任意 1s 内,接口的请求次数都不能大于 K 次
-
维护一个 K + 1 的循环队列,用来记录 1s 内到来的请求
- 当收到新的请求时,将与这个新请求的时间间隔超过 1s 的请求,从队列里删除
- 查看循环队列中是否有空闲位置,如果有的话,把新请求存储在队尾位置,如果没有,说明这 1s 内的请求次数已经达到了 K 次,拒绝此次请求
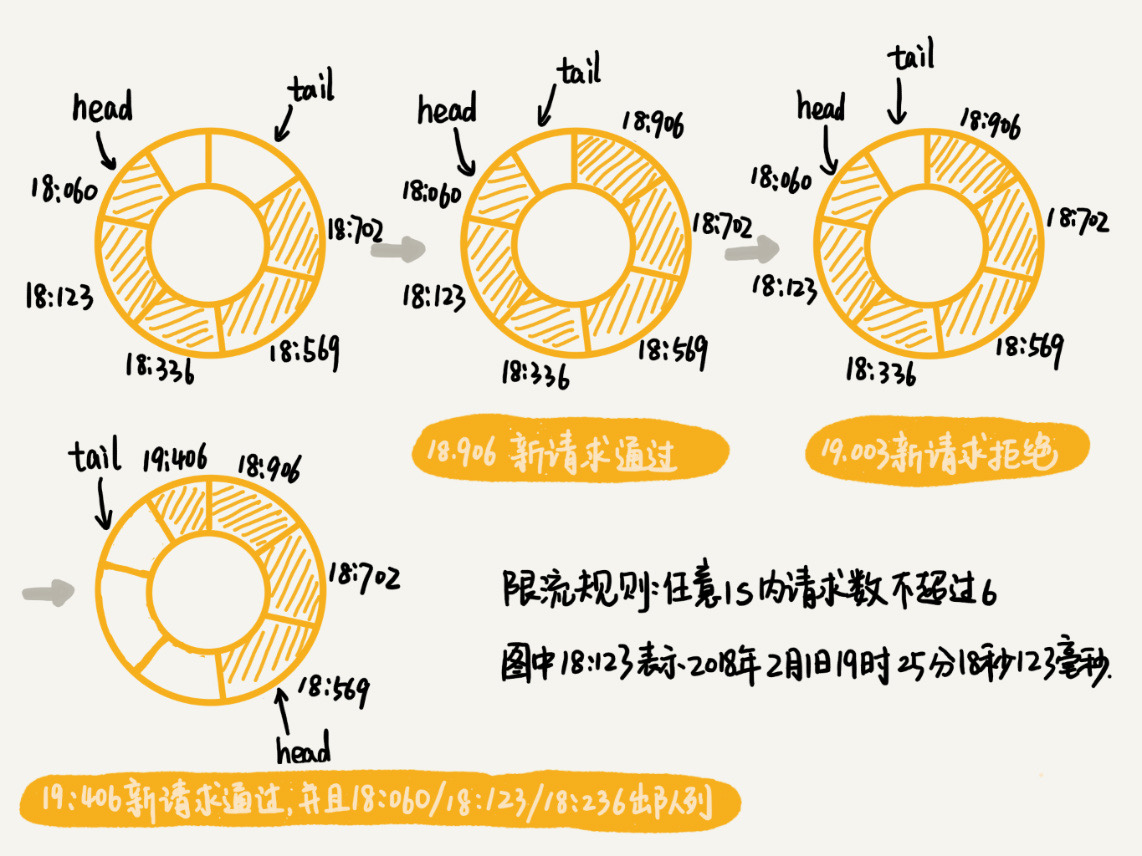
滑动时间窗口
-
-
更多的平滑算法