Redis 常用的数据类型
列表 list
- 当列表中保存的单个数据小于 64 字节,且列表中数据个数少于 512 个,将会使用压缩列表,否则使用的是双向循环链表
- 压缩列表 ziplist,Redis 自己设计的一种数据结构
-
类似于数组,通过一片连续的内存空间来存储数据,允许存储的数据大小不同
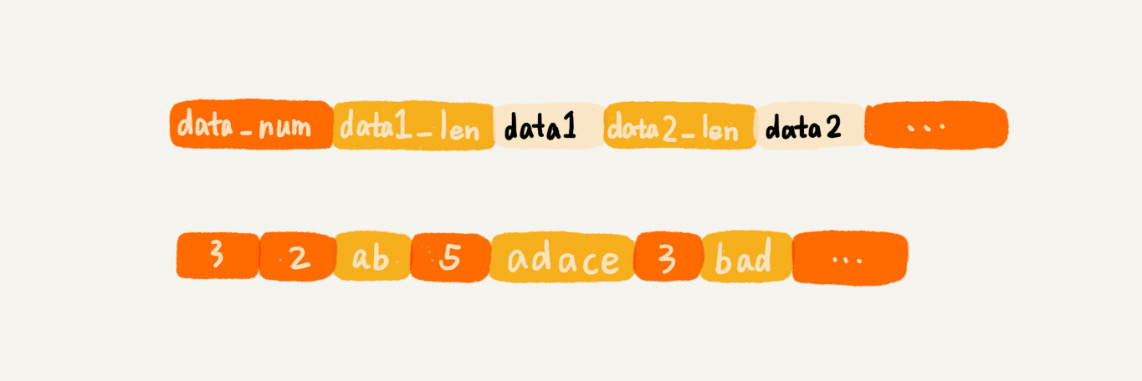
压缩列表 -
压缩列表相比于数组,节省内存,而且能够支持不同类型数据的存储
-
- 双向循环链表
- Redis 中会额外定义一个 list 结构体,包含链表的首、尾指针、长度等信息,使用起来十分方便
字典 hash
- 当字典中柏村的键和值的大小都小于 64 字节,且键值对的个数小于 512 个,将会使用压缩列表,否则使用的是散列表
- 散列表 MurmurHash2
- 使用 MurmurHash2 哈希算法作为哈希函数,运行速度快、随机性好
- 出现哈希冲突时,使用链表法解决
- 支持散列表的动态扩容、缩容
- 当装载因子大于 1 时,触发扩容,将散列表扩大为原来的 2 倍左右,具体的值通过计算得到
- 当装载因子小于 0.1 时,触发缩容,将散列表缩小为原来的 1/2 左右,具体的值也是通过计算得到的
- 参考 https://github.com/antirez/redis/blob/unstable/src/dict.c
- 在扩容、缩容的过程中,需要做大量的数据搬移和哈希值的重新计算,会比较耗时,所以 Redis 使用渐进式扩容缩容策略,将数据的搬移分批进行
集合 set
当存储的数据都是整数,且存储的数据元素个数不超过 512 个时,将会使用有序数组,否则使用的是散列表
有序集合 sortedset
当存储的所有数据的大小都小于 64 字节,且元素个数少于 128 个时,将会使用压缩列表,否则使用的是跳表
Redis 的数据持久化(数据结构的持久化)
- 清除原有的存储结构,只将数据存储到磁盘中。当需要从磁盘读取到内存中时,再重新将数据组织成原来的数据结构
- 从磁盘读取到内存中,将数据组织成原来的数据结构,可能会消耗不少的时间
- 保留原来的数据格式,将数据按照原有的格式存储在磁盘中