搜索引擎主要构成部分
搜索
通过爬虫爬取网页
分析
将网页内容抽取、分词,构建临时索引,计算 PageRank
索引
通过分析阶段构建的临时索引,构建倒排索引
查询
根据倒排索引获取相关网页,计算网页排名,返回查询结果
搜集
实现要点
- 将整个互联网当作一个非常庞大的有向图,把每一个页面当作一个顶点,如果某个页面包含另一个页面的链接,则在这两个页面(顶点)之间,连出一条有向边
- 利用图的遍历算法(广度、深度优先搜索算法),来遍历整个互联网中的网页
- 采用广度优先搜索算法
- 先爬取一些知名(权重较高)的网页,作为种子网页链接,放入到队列中
技术细节
- 待爬取网页链接文件 links.bin
- 将 links.bin 作为爬虫待爬取页面的队列,即广度优先搜索中的队列
- 每次从 links.bin 中取出网页链接爬取对应的内容
- 将爬取网页内容中的链接存储到 links.bin 中,实现断点续爬
- 网页判重文件 bloom_filter.bin
- 使用布隆过滤器,来对已经爬取过的网页进行判重处理
- 定时地将布隆过滤器存储在磁盘上,写入 bloom_filter.bin 中,实现断点续爬不会重复爬取
- 原始网页存储文件 doc_raw.bin
-
将多个网页存储在一个文件中,每个网页之间用标识符分割,方便后续读取
- 对每个文件的大小做限制,当文件大小超过限制时,创建新的文件
-
网页链接及其编号的对应文件 doc_id.bin
- 对每个网页分配一个唯一的 ID,可以按照网页被爬取的先后顺序,从小到大依次编号
-
links.bin、bloom_filter.bin 供爬虫使用,doc_raw.bin、doc_id.bin 为搜集阶段的成果,供后续使用
-
分析
抽取网页文本信息
- 根据 HTML 标签抽取网页中的文本信息
- 去掉不需要的标签,如 JavaScript 代码、、、 标签中的内容
- 去掉所有的 HTML 标签
- 使用 AC 自动机多模式匹配算法,在整个网页的字符串中,一次性的查找多个关键词
分词并创建临时索引
-
确定分词的规则,如 基于字典(词库)和规则的分词方法
- 字典中包含大量常用的词语(可以直接从网上 download)
- 基于词库,采取最长匹配规则,对文本进行分词
- 可以将词库中的单词构建成 Trie 树
-
构建临时索引 tem_index.bin
-
分词之后,得到网页对应的一组单词列表,将网页和对应的单词列表之间的对应关系,写入到一个临时索引文件中,其中单词列表使用单词编号(为了节省存储空间)
 -
将单词编号和单词的对应关系,存储到文件 term_id.bin 中
- 使用给网页编号类似的方法给单词编号
- 使用散列表来记录已经编过号的单词
-
-
tmp_index.bin、term_id.bin 供后续构建索引使用
索引
-
使用多路归并排序的方式,将分析阶段产生的临时索引,构建成倒排索引 (Inverted Index) index.bin
-
对临时索引,按照单词编号的大小进行排序,由于临时索引的文件大小一般都很大,所以使用“归并排序”的处理思想,先把临时索引文件分割成多个小文件,在对每个小文件独立排序,最后合并在一起(实际应用中可以直接使用 MapReduce 处理)
-
临时索引文件排序后,相同的单词被排列到了一起,顺序地遍历排好序的临时索引文件,将每个单词对应的网页编号列表存储在倒排索引文件中 index.bin
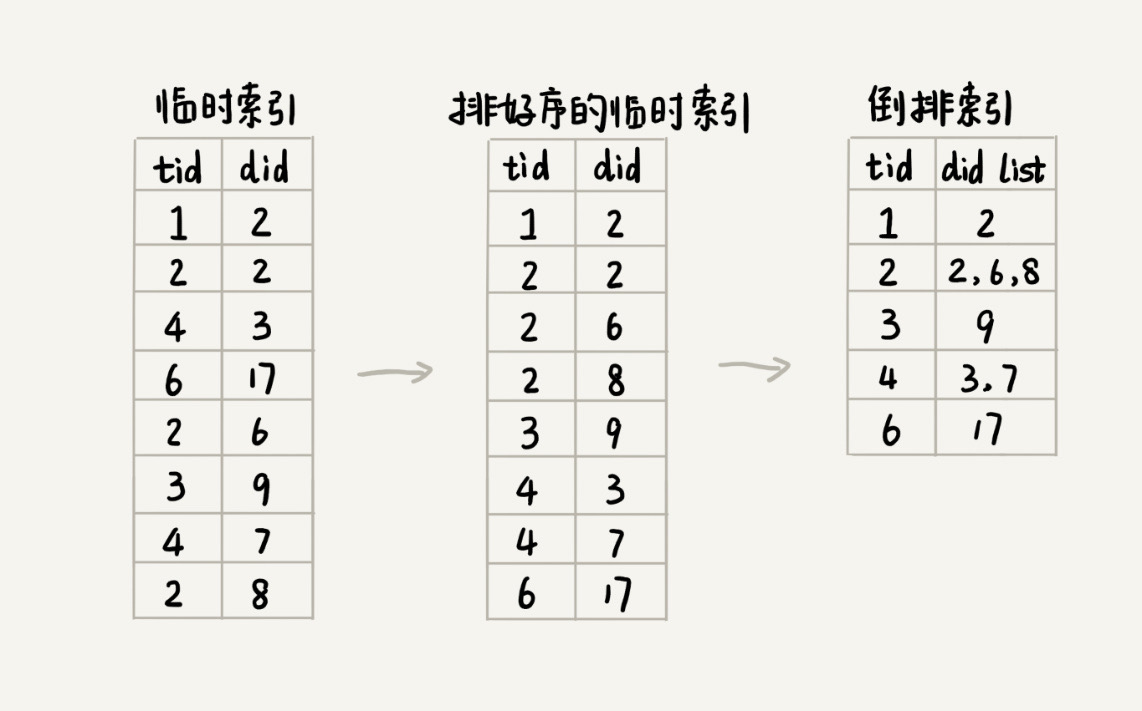
临时索引 -
倒排索引中记录了每个单词以及包含它的网页列表

倒排索引
-
-
生成每个单词编号在倒排索引文件中的偏移位置 term_offset.bin,快速地查找某个单词编号在倒排索引中存储的位置

偏移位置 -
index.bin、term_offset.bin 供后续查询使用
查询
- 经过上面三个阶段之后,得到以下文件
- doc_id.bin,记录网页链接和编号之间的对应关系
- term_id.bin,记录单词和编号之间的对应关系
- index.bin,倒排索引文件,记录每个单词编号及对应包含它的网页编号列表
- term_offset.bin,记录每个单词编号在倒排索引中的偏移位置
- 将 doc_id.bin、term_id.bin、term_offset.bin 文件中的内容,以散列表的结构加载在内存中
- 当用户输入搜索文本时,先对用户的输入文本进行分词处理,得到 k 个单词
- 在 term_id.bin 对应的散列表中查找这 k 个单词对应的单词编号,k_ids
- 在 term_offset.bin 对应的散列表中查找 k_ids 对应在倒排索引文件中的偏移位置,k_offsets
- 在 index.bin 文件中,查找 k 个单词对应的包含它们的网页编号列表,k_web_ids
- 使用散列表统计 k_web_ids 每个网页编号出现的次数,次数越多说明包含越多的用户查询单词
- 按照出现次数的倒序,在 doc_id.bin 中查找对应的网页链接,分页展示
相关算法
- 计算网页权重,PageRank 算法, https://zh.wikipedia.org/wiki/PageRank
- 计算查询结果排名,tf-idf 模型, https://zh.wikipedia.org/wiki/Tf-idf